Getting started with your Optimization Strategy
This post is an edited transcript of our recent conversation with Nick So, Director Optimization at WiderFunnel on our Masters of Growth Podcast.
Use a framework for generating hypotheses
The first thing that you’ll need if you want to optimize is a framework for coming up with ideas on elements to test and modify. In other words, to come up with decent hypotheses, you need to have the right mix of creativity and data comprehension strategies.
It’s not a matter of just churning out ideas like spaghetti, throwing them at a wall and hoping they stick. You’ll need a sense for which insights are useful, both in the ideation phase and in the analytical phase.
It is very helpful if you have some sort of framework or process in place, so when you gather data whether user research, data analytics, or results from past experiments, you can turn them into actionable insights and generate new strategy points.
One example of this kind of framework is the WiderFunnel Infinity Optimisation Process:
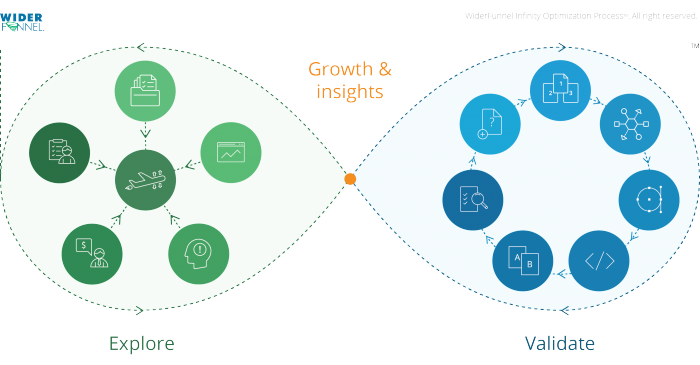 The folks at WiderFunnel divide the optimization approach into two parts: the creative phase and the validation phase. In the creative phase, the idea is to search for insights from analytics, look at user research, persuasion, and marketing principles, and consider consumer behavior, taking into account the business contacts and business goals. All this information is collected and sorted, then plugged into the next phase for validation.
The folks at WiderFunnel divide the optimization approach into two parts: the creative phase and the validation phase. In the creative phase, the idea is to search for insights from analytics, look at user research, persuasion, and marketing principles, and consider consumer behavior, taking into account the business contacts and business goals. All this information is collected and sorted, then plugged into the next phase for validation.
The validation phase is all about experimentation: everything should be confirmed or dismissed by data. All these insights from the creative side are examined and validated using actual tests and hypotheses.
The third part of this framework is the LIFT model, which may be familiar to CRO enthusiasts. It basically weighs the positive characteristics of a page against the negative characteristics.
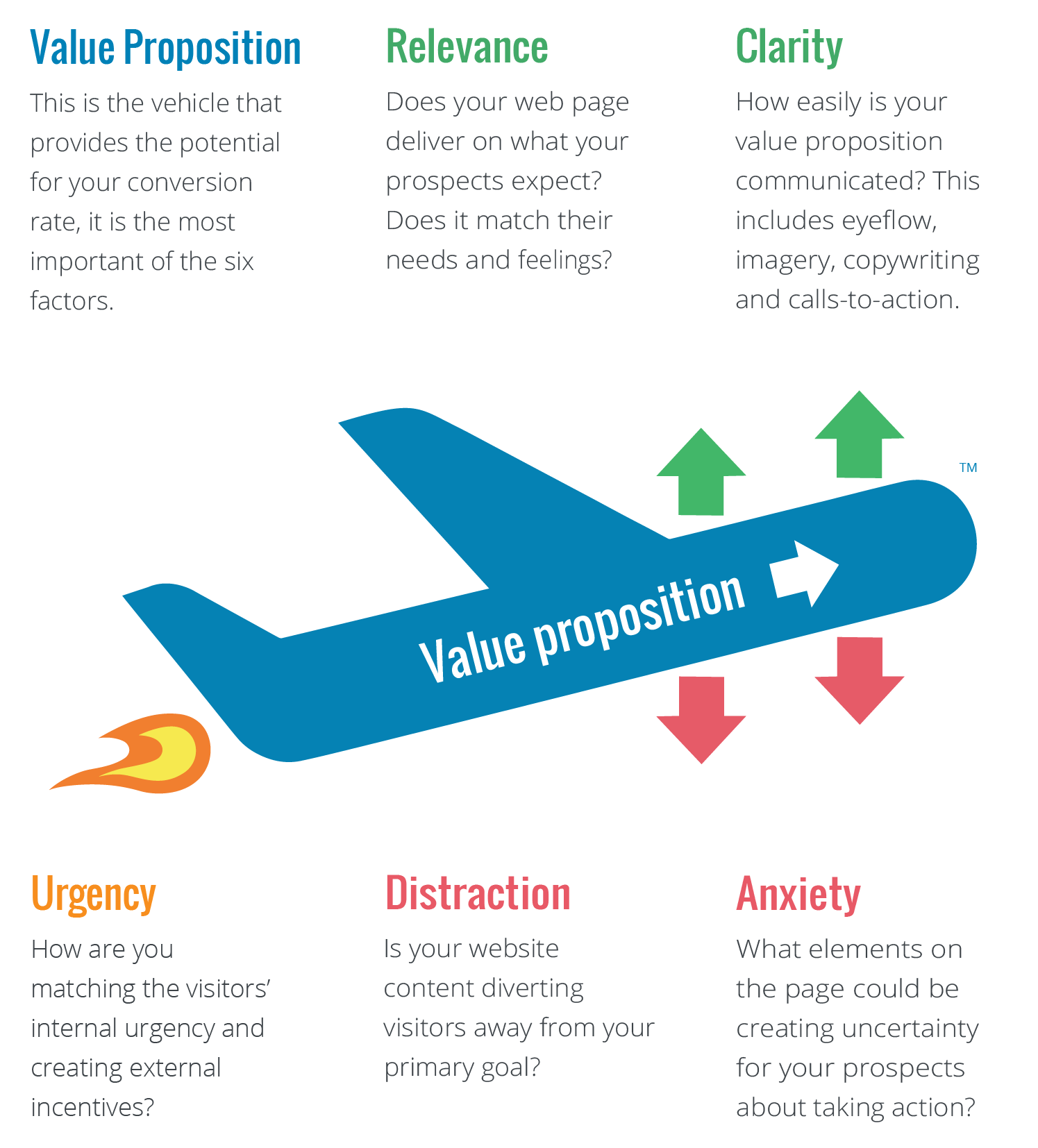
What the LIFT Model aims to do is to translate all these different data points, from marketing psychology or data analytics to user research, and to filter all those different elements into a common language that everyone across the organization can comprehend. When a designer says, “I don’t like how this looks,” the statement is not yet actionable, even if it might be justified. What does it tell us? But the LIFT Model allows us to understand the sentiment better: perhaps the element was unclear to the user, distracting from the value proposition. So the model takes away the subjectivity marketing and forces people to be accountable for their ideas.
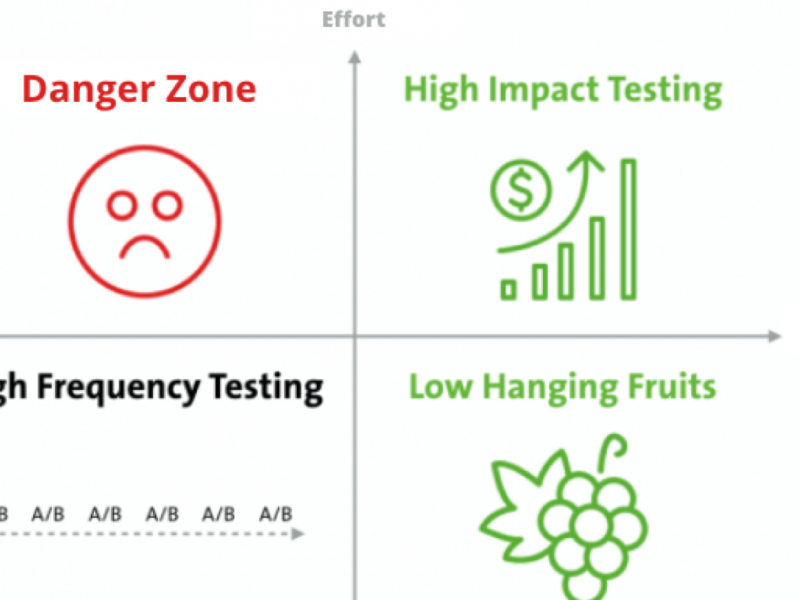
Don’t try to test too many things at once
Once you’ve developed a few hypotheses for testing, it is not uncommon for people to get excited about the experimentation and start running several different tests at the same time. If this is you — think about the quality of your hypotheses. If you’re trying to test too many variables at once, you could be increasing the risk of false positives. Keep an eye on statistical significance and sample sizes: that way you can avoid making mistakes by being overzealous.
Start your Optimization Program today!
Try iridion PREMIUM for 30 days free. No credit card required!


More Uplift, More Insight – 4 unseen factors in successful optimization
Every optimizer knows that a test can end with outstanding uplift one day, and the next day you’re left wondering why the last test failed. Conversion-optimization is more drudgery than the superhero images would have us believe.
Sooner or later, there are important questions that an optimizer needs to answer:
- “How can I separate bad ideas from good, early on?
- “How can I increase my rate of success?
- “How can I improve results and uplift?
Consider an ocean voyage… but on a stormy sea. It takes a stable craft, reliable navigational equipment, a hard-working crew and a captain who knows what he’s doing.
We have been at the business of sailing the “Sea of Conversion” for many years. What we know for sure is that every detail is important and every aid is relevant. To cross that sea with certainty, we’ve put together the most essential components for a successful voyage.
1. Build the boat – identify weak points and generate measures for optimization
The Alpha and Omega of any successful experiment comprises the ideas and the hypotheses at its foundation. Every successful experiment draws on a good idea or a good hypothesis at its heart. To tackle the right issue, it’s important to ask the right question.
Qualitative analysis leads to new ideas
To generate measures for optimization, important factors in addition to knowledge on the metrics for the site are creativity, empathy and a sound understanding of user behavior. Models can help guarantee continual high performance, making sure that input goes beyond mere subjective opinion and that user purchasing behavior is always being questioned.
The “seven levels of conversion” framework
Why should the seven levels framework be used?
The framework allows a simpler pick-up on the user’s decision-making process, thereby identifying weak points. You can see through the user’s eyes and comprehend a website visit from that perspective.
How do I benefit?
The weak points that are identified by using the framework offer new sources for optimization measures. If the framework is used regularly it helps to derive the right ideas or hypotheses for the particular website and target group.
We have digitalized the seven levels framework for the first time and we are making it accessible through Iridion. It has never been easier to use the framework.
2. Sail in the right direction – prioritize optimization measures the right way
Regardless of whether the issue concerns a sophisticated hypothesis or a quickly-formulated optimization idea, sooner or later the question will arise: How do you objectively evaluate and determine what’s worth testing?
Usually, assumptions that appear logical form the foundation for deciding what needs to be tested:
- How much traffic does the particular site see?
- Which sites have the highest drop out rate?
- What’s easy to implement?
- Or will the HIPPO (highest paid person’s opinion) simply once more determine how to go forward?
In reality, decisions are often made based on these or similar criteria. To reach well-founded decisions, however, it is important to use an evaluation system that is as objective as possible and one that incorporates all influencing factors that are relevant to the optimization measures.
Systems that can help in prioritizing are, for example:
- The PIE Framework by WiderFunnel
- CHPL-Scoring by konversionsKRAFT
What good will it do me?
Resources are often limited, and it is therefore particularly important to do testing only where a good cost-benefit relationship exists. The scoring provides a precise tool to isolate measures that are really worth the expense of an A/B test.
Tip:
With a system like that, personal HIPPO preferences can also be included and possibly weighted more highly. The chances of making all stakeholders happy and reaching a consensus increase enormously because of this system.
We have integrated CHPL scoring, which has been proven in practice, into Iridion and made it accessible to everyone.
3. Keep the logbook current – control your experiments
It isn’t easy, getting an overview of all of the information relevant to an experiment. But knowing what happened in all of your past and present experiments at any given time is essential in order to make meaningful decisions or to pass knowledge gained along to the right people.
The following questions should be answered in order to continually cultivate information that relates to the CRO process:
- What’s being tested?
- What is the current state of the current tests?
- Which tests were successful and which were not?
- Which hypotheses / ideas or weak points were tested?
- How do I quickly set up a results report?
Iridion helps answer these and other questions at any time.
Tools that can help organize tests (but are not directly associated with Iridion)
- Excel to prepare test results
- Powerpoint/Keynote for results reports
- Dropbox or Fileserver for Wireframes, concepts and other supplements.
- The particular testing tool for all test-related data and visualizations
- A PM Tool that coordinates and allocates the particular test status
- Google Docs for collaborative work
These solutions are not centralized and are very hard to automate, so Iridion puts everything into one solution.
Iridion makes it possible to obtain an overview at any time, and to grasp all important information prepared in one view.
4. Maintain knowledge and make it reusable – maintain the logbook
Information that results from testing is often developed with difficulty only. It is important that knowledge gained be put to use and retained after implementing the change. Every test can lead to an improvement in the foundation for follow-up decisions.
A typical scenario
“Two years ago Mr. Schulz, the responsible person at that time, had already tested a similar scenario. Unfortunately, Mr. Schultz is no longer working with us and knowledge acquired at that time is no longer available. What now?
A “CRO” Wiki
Quality and number of A/B tests are not the only factors crucial to guaranteeing continued forward movement. The application of knowledge already obtained is a relevant influencing variable to achieve a greater probability of success and an advantage over the competition.
Why do I need this?
Optimization always includes a learning curve. Optimization measures can therefore go through a number of cycles. If care is taken to avoid loss of available knowledge and, instead, that knowledge is used meaningfully, then hypotheses and test concepts can be better tuned to a particular target group.
The following tools help make knowledge permanently accessible:
- Internal Wiki for knowledge storage for test concepts (time consuming)
- Excel as storage for test results (not fit for teams)
- A PM tool can maintain and characterize knowledge in the ticket system (often ill-suited for test results)
- PDF’s with test reports on the server (not easily searchable)
Whether there is a significant uplift or not, every test still provides knowledge that should be recorded. Iridion makes the development of a CRO-Wiki possible.
Upshot – holding to a course isn’t easy
Every phase of the trip makes use of various methods and tools. Which ones– and how many of those are suitable– are often difficult to determine. In the end, the efficiency of the measures should increase and the outcome to the conversion optimization should be influenced positively.
We found it inconvenient, having to refer back to a hodgepodge of various tools during our daily work in order to master our optimization procedure.
We developed a tool that displays the complete flow of work centrally, in one solution– to simplify the CRO every day and to design it as efficiently as possible – Iridion.
Learn more about the tool here – Iridion – Welcome to our world.
Start structuring your Experiments today!
Try iridion for free as long as you want by signing up now!





Checklist: 15 simple things for trouble-free A/B tests
#1 No deployments during the test run
Changes or bug fixes, even if they appear small and simple, can lead to complications as the test plays-out. This is above all important for <tag> based testing tools. If there is a roadmap with a definite deployment schedule, tests can be carried out before or after. If a deployment is not to be impeded during a test runtime, talk to your developer ahead of time. With a copy of the running test and a play-out, e.g. onto a staging server, possible conflicts can be recognized early on and the test can be adjusted. You would like to estimate the test runtime? Our rule of thumb for an average test runtime:My colleague Manuel Brückmann gets into this topic in detail in his article Why you’re shutting down your A/B-test too soon.A test should run at least 2 – 4 weeks and contain at least 1,000 – 2,000 conversions per variation. Special events should take placed during this period (newsletter, TV-spots, sales, etc.). The greatest possible number of channels should be displayed (total traffic mix, either through targeting in the preliminary stage or segmentation in follow-up). If the test has reached a minimum statistical significance of 95% (two-tailed, that is positive as well as negative) and if this is stable, then the test can be stopped.
#2 Be aware of contrast
The combination of different adaptations often makes contrast-rich testing possible. Too high a contrast makes a subsequent analysis of the most effective leverage difficult, however. Additionally, expenses for implementation and quality assurance will rise. My recommendation would therefore be: Check a big adjustment in a first test. Undertake further adjustments in following sprints and validate.#3 Be aware of the worst-case scenario
Often, with a wide product assortment, there are divergent illustrations in the template, or the header changes through progression of the site, e.g. UVPs are presented bolder in the checkout. This can lead to bigger or smaller problems in development as well as in quality assurance. By setting-up a worst-case scenario in the preliminary stage (e.g. in the form of an impediment backlog) special cases can accordingly be observed as early as development. With this list, quality assurance can offer an optimal check of all possible scenarios. Ask your customers about special cases (special sizes, particular product categories such as, e.g., accessories, etc.). This makes it easier for both sides the intercept deviations.#4 Agility vs. perfection
Often, A/B tests are expected to be implemented to complete perfection. But after a number of weeks of tuning cycles, development, quality assurance and test runtime, however, the result is unsuccessful. We like to say,“a test is not a deployment”. Important: This is not intended to indicate a reduction in the quality of test implementation or quality assurance. Instead, the issue concerns implementing minimal details, the effect of which, however, are questionable on a visitor. Should you be confronted by this problem at the next occasion, simply pose the following question: “Would I not buy this product because, e.g., the font size, line spacing or margin width isn’t right?”#5 Be aware of lateral entry
A lateral entry into a test should always be noted. SEA, SEO or established customers should under circumstances be shown a changed page or be redirected to another page. In the former case, serious errors could arise, caused by the play-out of the test.#6 Take note of the test starting point and any discrepancy in the URL structure
A look should be given to a possible discrepancy in the URL structure, above all when carrying-out multi-page or funnel tests. Should the structure unexpectedly change, in the worst case the targeting of the testing tool might no longer be effective. This results in participants no longer being able to see the test variation. For external providers, for e.g. methods of payment, conversion and revenue can be lost – through a missing return path on the thank you page.#7 No test without targeting
Excluding certain devices / browsers is not necessary if quality assurance can guarantee error-free test play-out onto all end-user devices with the associated browsers. In the rarest of cases, however, is this actually possible. A whitelist, a listing of all end-user devices as well as browsers that are to be checked by quality assurance, can exclude potential sources of error. It is advantageous if this list is already defined before development release. The current hit rates from an existing web analytics / reporting tool, such as Google analytics, assist in this regard.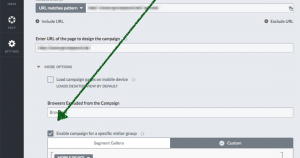 The somewhat hidden custom-targeting in Visual Website Optimizer. The upper target, for example, for the exclusion of mobile end-user devices. The lower target comprises a regular print out, whereby only desired browsers (whitelist) are permitted into the test.
The somewhat hidden custom-targeting in Visual Website Optimizer. The upper target, for example, for the exclusion of mobile end-user devices. The lower target comprises a regular print out, whereby only desired browsers (whitelist) are permitted into the test.
#8 Exclusion from measurement
Who are the daily users on a site? Aside from your customers, these are often suppliers, such as call-centers or even colleagues in the office next door. But this can render your results erroneous. Therefore, exclude your own IP-address as well as that of internal and external employees from the measurement. Note: not every tool provides the opportunity to filter-out IP addresses from the results afterwards.#9 Browsers get old too
Older browsers, such as IE 7 and 8, die off. By looking at traffic numbers, older browsers can often be neglected. Based on experience, browsers such as IE 7 or IE 8 require enormous additional time in development and quality assurance. Source: http://www.w3schools.com/browsers/browsers_stats.asp
Source: http://www.w3schools.com/browsers/browsers_stats.asp
 According to statistics from December 2014, of 1,000 visitors we had an allotment of 1.5% of visitors using IE 7 and 8. This corresponds to 15 visitors.
According to statistics from December 2014, of 1,000 visitors we had an allotment of 1.5% of visitors using IE 7 and 8. This corresponds to 15 visitors.
#10 Are iFrames available?
External service providers will gladly expand your site via functions. It can happen that these functions are implemented via an iFrame. iFrames can be manipulated if they are located in the same domain. If this is not the case, your testing tool must be implemented in the supplier domain. If you are lucky this is possible. In most cases, however, it is not. Check the concept together with your developer in advance for feasibility.#11 Take note of quality assurance expense
The time required for quality assurance is often underestimated. Typical, problematic cases involve tests on the product detail page or checkout. The expense can climb exponentially. Talk to your quality assurance in advance, in order not to be surprised. Here is an example of a simplified calculation for the time required for checkout tests: variations x Browser x Pages x Types of customers x Types of delivery x Types of payment x Special cases = Pages to be considered variationen x Browser x Seiten x Kundentypen x Lieferarten x Zahlungsarten x Sonderfälle = Zu betrachtende Seiten Pages to be considered x Time per page = Time needed by quality assurance A test with two variations for only four browsers, with five pages, three types of delivery and five types of payment corresponds to 600 pages to be investigated. At only two minutes per page the time used is 20 hours.#12 Is the product diversity known?
The product detail page frequently offers great optimization potential. From small adjustments to complete restructuring. Often, however, the quantity of products and their varying depictions (special cases) do no get attention. The result is necessary adjustments for development and additional expense for quality assurance. The consequence is a delay in the start of the test. You will find a multitude of differently structured product detail pages on Amazon.
In case you are not familiar with all possible special cases, seek out colleagues who can further help you. Combine the corresponding special cases before the test is conceived and provide the appropriate information to development and quality assurance.
Should it be too late for this or if unexpected problems arise, you should take note of the following: Can individual categories or brands be tested for the time being? This will make the start of the test possible and provides a buffer for adjusting the test to your entire assortment.
You will find a multitude of differently structured product detail pages on Amazon.
In case you are not familiar with all possible special cases, seek out colleagues who can further help you. Combine the corresponding special cases before the test is conceived and provide the appropriate information to development and quality assurance.
Should it be too late for this or if unexpected problems arise, you should take note of the following: Can individual categories or brands be tested for the time being? This will make the start of the test possible and provides a buffer for adjusting the test to your entire assortment.
#13 Take note of Ajax or the adjustment of product images
Not infrequently, changes are undertaken through dynamically reloaded content, e.g. information on inventory. But this is not always immediately obvious. In the best case, there is merely added expense for development, in the worst case implementation is not possible. When product images are being reduced or enlarged, the quality of the images must be noted. A pixelated image prevents optimal product illustration. When enlarging thumbnails, it quickly becomes clear that image quality is no longer adequate.
When enlarging thumbnails, it quickly becomes clear that image quality is no longer adequate.
 Reloaded content is not immediately available for manipulations. Whether this can lead to problems in the implementation of tests in this case must be checked in detail.
Take note of reloaded content and take development into account early on. The enlargement of product images as well as the addition of larger content (text or image) should be tested in advance in order to assure feasibility.
Reloaded content is not immediately available for manipulations. Whether this can lead to problems in the implementation of tests in this case must be checked in detail.
Take note of reloaded content and take development into account early on. The enlargement of product images as well as the addition of larger content (text or image) should be tested in advance in order to assure feasibility.